
Since the release of WebContainers about a year ago, we have been regularly asked why they don’t work in non-Chromium browsers. Some people think it’s because we use Chrome-specific APIs to make WebContainers work, which is not the case. As much as we ourselves want this technology to work across all browsers, it’s not as simple as just turning on a few knobs.
To understand all of this, we have to look inside the technology stack that we use. There’s one crucial part that WebContainers need in order to work, which is SharedArrayBuffer, or SABs. SharedArrayBuffer is available in all browsers, however, it’s not available by default.
The story of SharedArrayBuffer
Under the hood, WebContainers use SABs heavily for communication. A SharedArrayBuffer represents a raw binary data buffer which can be shared with, for instance, multiple Web Workers. One of its features is that it allows for synchronous communication between workers by leveraging the Atomics APIs.
At the beginning of 2018, SharedArrayBuffer was disabled together with high-resolution timers by all browser vendors in light of the Spectre vulnerability. Spectre allows an attacker to potentially read any data that is loaded inside the same browsing context group.
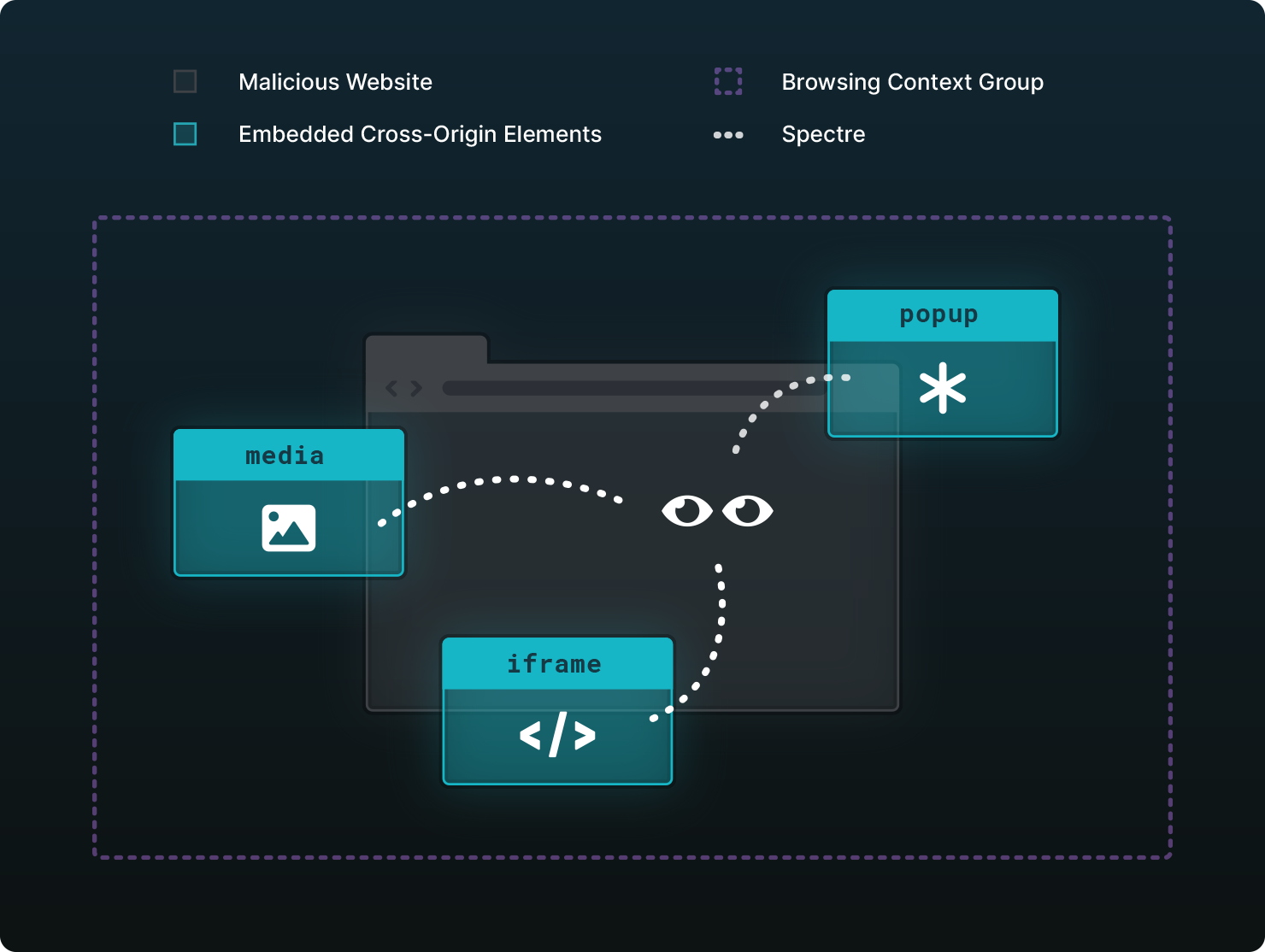
A browsing context is an environment in which a browser renders a document. This is usually a tab but can also be a window or an iframe. Every browsing context has a specific origin which is defined by the protocol, domain, and port of the URL. When the protocol, domain, and port of two browsing contexts match, they have the same origin. A browsing context group is a group of browsing contexts like tabs, windows or iframes which share the same context. For instance, a document gets rendered inside a tab, that tab is the browsing context. The document opens a popup window which has its own browsing context, but they both share the same parent context. Because they share the same context, they are both grouped together which means that they can interact with each other via DOM APIs such as window.opener.
By measuring the time certain operations take, an attacker can guess the contents of the CPU caches. This, in turn, allows the attacker to read the contents of the process’ memory. Timing attacks are possible with low-resolution timers, but can be sped up by using high-resolution timers. This is the reason why they were disabled in light of this vulnerability.
In 2020, browser vendors re-enabled the use of SharedArrayBuffer after a new secure approach had been standardized. These mechanisms are crucially important; however, they don’t prevent the exploitation of the Spectre vulnerability. Instead, the mechanisms drastically reduce the attack surface by protecting sensitive data from being present in parts of the memory from which they can be read by the attacker. To be able to use SABs, certain requirements have to be fulfilled as they are not enabled by default.
The baseline requirement is that your document needs to be in a secure context. In short, this means that the document has to be served over HTTPS. If you load a document inside an iframe, its context is not considered secure if an ancestor was not served over HTTPS.
So far so good. Nowadays, most websites are served over HTTPS so that requirement shouldn’t be too hard to fulfill. But what comes next is a whole different level. The second requirement is that your document has to be cross-origin isolated. Let’s discuss what that entails!
Cross-Origin isolation
Together with HTTPS, cross-origin isolation enables the use of SharedArrayBuffer. But not only that, it also enables performance.measureUserAgentSpecificMemory() to measure your webpage’s total memory usage. Because of Spectre, high-resolution timers were disabled as well. With cross-origin isolation, the resolutions of perfomance.now() and performance.timeOrigin drop from 100 microseconds or higher to 5 microseconds or higher, thus re-enabling high-resolution timers as well.
If cross-origin isolation gives us all these benefits, why not enable them on all websites and call it a day? To answer that question, we first have to look what enabling this actually means.
Enabling cross-origin isolation
To opt into a cross-origin isolated state, the main document has to be served with the following HTTP headers:
Cross-Origin-Opener-Policy: same-origin
Cross-Origin-Embedder-Policy: require-corp
If done correctly, you can check if your page is cross-origin isolated with window.crossOriginIsolated. Here’s an example that demonstrates how it works. Notice that you have to open the preview in a separate tab, which we’ll discuss later.
Let’s discuss the purpose of both headers and their impact on the website.
Cross-Origin-Opener-Policy
Enabling the COOP: same-origin header on the top-level document will create a separate browsing context group for a window opened from that document, unless they are in the same origin with the same COOP setting. Because of the separate browsing context group, mutual communication between both windows is disabled.
As an example, let’s take a look at the following scenario.
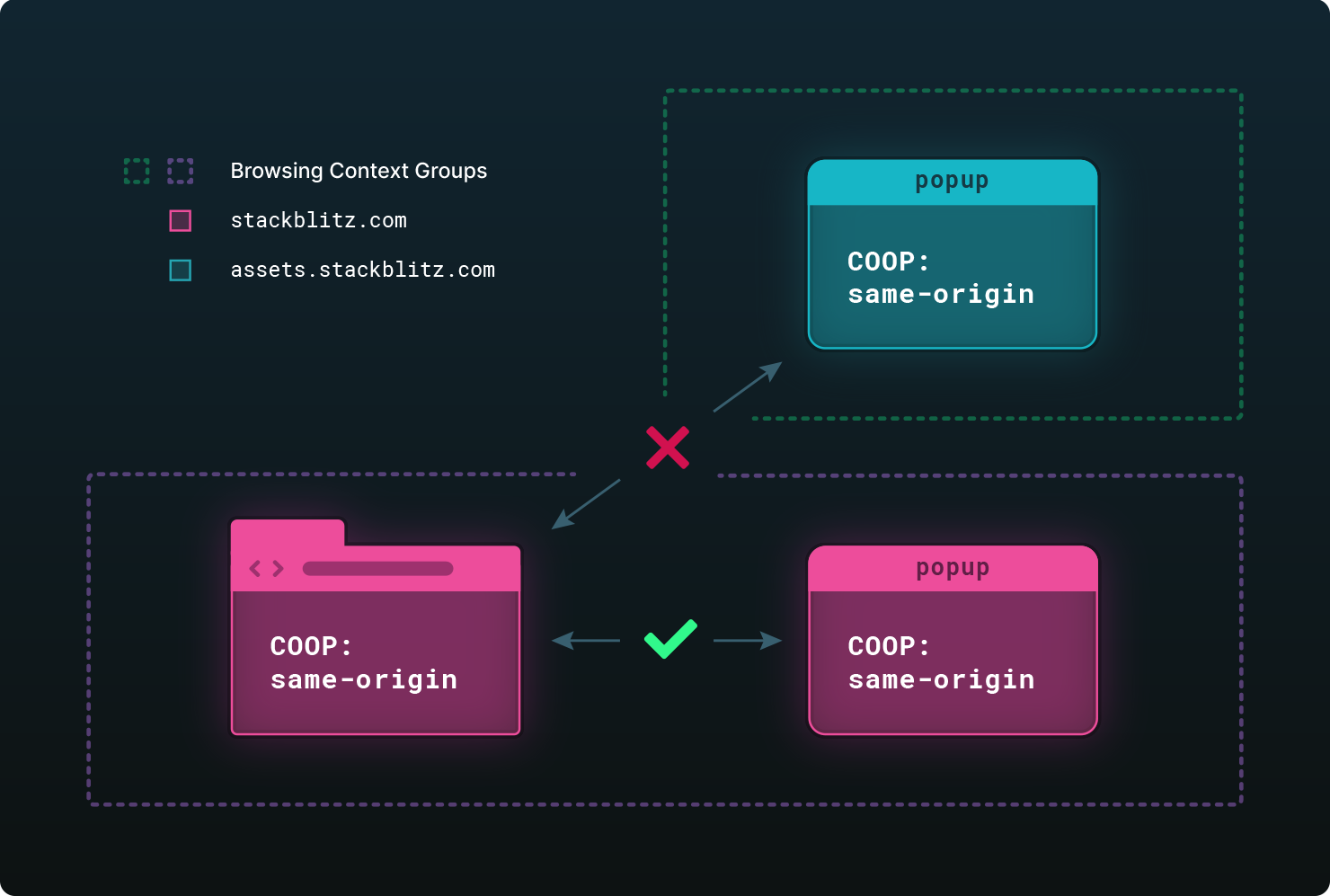
We have a top-level document with COOP: same-origin which opens two popups. One of the popups is opened from the same origin as the top-level document, stackblitz.com. Because they have the same origin, they reside in the same browsing context group, which allows for the interaction between the two documents. However, the second popup is opened from a different origin, assets.stackblitz.com, and thus resides in a separate browsing context group. Interaction between the two is impossible as window.opener in the popup will be null. Also, the .closed property of the opener’s reference will always return true.
Here’s an example demonstrating the effect of COOP: same-origin. Clicking the Same origin button, opens a page that belongs to the same origin as the main document. The main document can detect when the popup is being closed by the user. But when you open the cross-origin page, window.closed will be true and there is no way the opener can know when it’s effectively closed.
You can also use COOP: cross-origin, which allows for the interaction with cross-origin documents. This means that you are able to check if the window is closed. However, for your page to be cross-origin isolated, the Cross-Origin-Opener-Policy header has to be set to same-origin. This example features cross-origin setting live in action. When clicking the Cross origin button, the top-level document is able to detect the state of the popup.
Interactions that require cross-origin window interactions such as OAuth and payments will break. There is a discussion on exploring ways to allow cross-origin isolation through COOP: same-origin-allow-popups. But at the time of writing it doesn’t look like this will ship any time soon, if ever.
APIs like FedID, formerly known as WebID, or WebPayments, will eventually solve the issue by providing developers with a way to build robust OAuth or payment flows without pop-ups. However, these APIs are not there yet.
If you are blocked by this issue, you can always register for an origin trial until a solution is available. An origin trial is opt-in which gives your website a temporary exception and provides you with extra time to implement the necessary changes. However, you have to be aware of the fact that other browsers, like Firefox or Safari, do not have such mechanism. In Chrome, the origin trial will not be removed until this issue is resolved.
Now that we’ve discussed the COOP header, let’s advance to the Cross-Origin-Embedder-Policy header or COEP header.
Cross-Origin-Embedder-Policy
The COEP header determines if cross-origin resources can be loaded or not. Currently, the only valid value for Cross-Origin-Embedder-Policy is require-corp. If a document is served with this header, cross-origin resources can only be loaded if they explicitly grant permission to do so. If the resource does not grant permission, loading that resource will be blocked.
Permission can be granted in two different ways. The most well-known way for a resource to grant specific domains to load that resource, is via CORS. By setting the Access-Control-Allow-Origin header, the resource can grant permission for specific origins to load it. The second way is through the Cross-Origin-Resource-Policy, or CORP header. By serving a resource with Cross-Origin-Resource-Policy: cross-origin, it will grant permission to all cross-origin documents to load it.

The image shows a webpage which embeds multiple third-party resources coming from a different origin. The JavaScript file has the CORP header set to cross-origin, which means our website can load it. The image does not have the CORP header set but it uses CORS to grant permission for our website to load it. The video resource has the CORP header set but it is set to same-origin, which means loading that resource is blocked.
If CORS is enabled on external resources like images, scripts, stylesheets or videos, they have to be explicitly loaded by using the crossorigin attribute. The default value for this attribute is anonymous, which means that credentials such as cookies or http authentication will only be sent if the resources are fetched from the same origin. If the image is loaded from a different origin, all information is stripped so that only information publicly available is sent between client and server.
Let’s take a look at an example which shows the impact of embedding images when the top-level document is served with the COEP: require-corp header. The example demonstrates what we saw in the image above. Images will only load if they have CORS enabled in combination with the crossorigin image attribute, or if the image itself allows it through the CORP: cross-origin header.
Serving a document with the Cross-Origin-Embedder-Policy also impacts pages loaded through iframe. If the top-level document is served with COEP: require-corp, the document loaded inside the iframe should have the appropriate headers as well. This example demonstrates a document loaded inside the iframe with appropriate headers. The top-level document has the COEP header set and embeds two iframes. The first iframe loads stackblitz.com, which does not grant our document permission to load it. The second iframe loads a local file, served on the same origin. However, because the top-level document is served with COEP, the document loaded should also have the COEP header set. If the COEP header was not required on this document, it would get elevated permissions and would be able to load resources that could not be loaded by the top-level page itself. For that reason, the COEP header is required for same-origin documents loaded through an iframe.
Last but not least, importScripts() inside Web Workers is also affected by this policy. If the script is loaded from a different origin, the script has to be served with the Cross-Origin-Resource-Policy: cross-origin header. However, there is a difference between importScripts() inside a Web Worker and importing a script with a script tag. As mentioned before, a cross-origin script loaded with a script tag could also grant permission with CORS headers in combination with the crossorigin attribute. With importScripts, the CORP header is the only way of granting the permission because importScripts() does not have a crossorigin attribute which would enable CORS.
Cross-origin isolation in practice
Now that we’ve discussed how to enable cross-origin isolation, it’s easier to explain why it’s not always as simple in practice. For some websites, it might be as simple as just turning those headers on but for other websites, StackBlitz included, there’s much more to take into consideration.
Let’s recap the difficulties of applying those headers and what it means for StackBlitz.
COOP breaks OAuth
The Cross-Origin-Opener-Policy: same-origin header enforces separate browsing context groups for different origins. This implies that it’s impossible to communicate between the different browsing context groups. However, there are interactions that actually do require cross-origin window interactions like OAuth flows or payments. At the the time of writing, there’s no solution to this specific problem.
Unfortunately for us, StackBlitz uses GitHub OAuth as authentication flow. A possible solution would be to redirect the user to a page which is not cross-origin isolated. That page could then handle the authentication flow and redirect the user back to where they came from. If we want a more seamless integration, we have to rely on browser vendors to resolve this issue.
External resources
Due to the COEP: require-corp header, loading resources from a different origin like an asset server, will now require additional code changes. The asset server has to explicitly grant permission to be able to be loaded by your website. If the permission is not granted, it’s not possible to load those resources and they will break. We saw the problem in the image example serving the top level document with COEP.
As an application developer, we don’t always have full control over where the assets come from. Sometimes the only solution to the problem is proxying those resources through our own server and adding the appropriate headers.
The impact on StackBlitz is even bigger. We have control over most resources that get loaded by our website. However, we don’t have any control on the resources that users load while developing their application. This means that some applications might break if we turn these headers on. To solve this issue, we would first need to understand the problem and then apply the additional changes, like for instance the crossorigin image attribute, which wouldn’t be needed if an application was developed locally.
Embedding
Embedding a cross-origin isolated website inside a context that’s not cross-origin isolated through an iframe will not work either. A document inside an iframe will not be cross-origin isolated if one of its ancestors is not cross-origin isolated either. This means that if you rely on SharedArrayBuffer or other APIs which require cross-origin isolation, your website will be broken inside embeds.
Let’s take a look at an example that illustrates embedding with cross-origin isolation. Make sure to pop open the preview in a separate window. As you will notice, the top-level document is not cross-origin isolated as it does not have the required headers set. However, the iframe document is served with the headers to make it cross-origin isolated. Because it’s embedded inside a non-cross-origin isolated context, the iframe itself is not cross-origin isolated either. In the example project, you can click the link inside the iframe to open it in a new window, which will then indicate that it is cross-origin isolated.
This is exactly what would happen if StackBlitz enabled these headers. All websites that rely on embedding StackBlitz WebContainers-based examples would now be broken, unless it is ensured that they are cross-origin isolated as well.
Cross-origin isolation with credentialless
Enabling cross-origin isolation turned out to be difficult to deploy at scale. The reason is that all subresources have to explicitly opt in by granting permission and developers don’t always control the subresources. For some sites this might be fine but it creates dependency problems for sites with user-generated content like forums, Google Earth, and StackBlitz. Google felt the pain of switching to cross-origin isolation at scale as well. And this is why they came with a new proposal: Cross-Origin-Embedder-Policy: credentialless.
With the new proposal, you will be able to enable cross-origin isolation with the following headers:
Cross-Origin-Opener-Policy: same-origin
Cross-Origin-Embedder-Policy: credentialless
The idea behind the credentialless proposal is to invert the decision of loading resources. With require-corp, it’s the resource itself that decides if it can be loaded or not by explicitly granting permission. With credentialless, it’s the website that decides how external resources are loaded.
If you set the COEP header to credentialless, cross-origin requests without CORS enabled will strip off all credentials, such as cookies or HTTP authentication, from the request. This means that the requested cross-origin server will not be able to respond with sensitive resources and the response will only contain publicly available information.
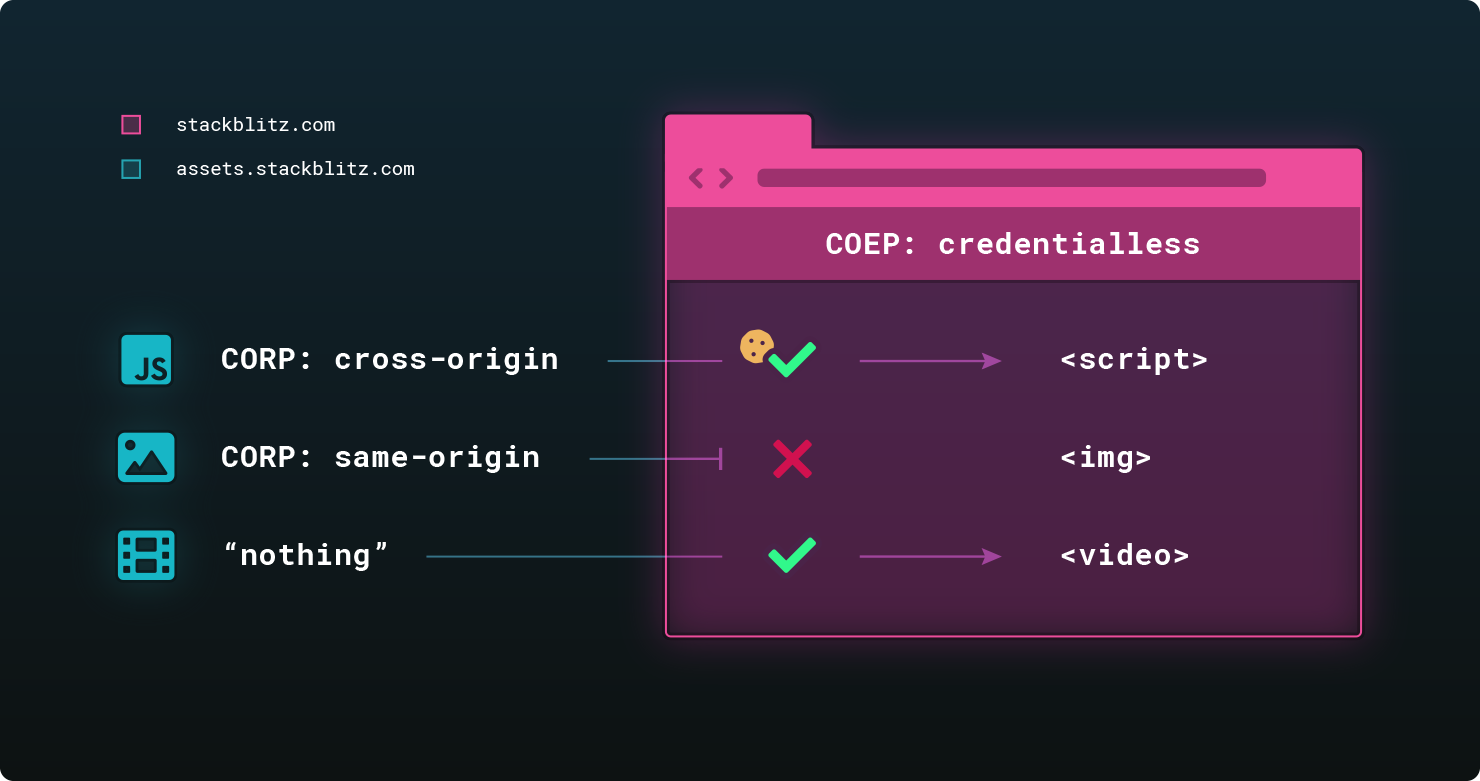
As you can see in the image, credentials will not be stripped off if the loaded resource has the Cross-Origin-Resource-Policy set to cross-origin. The resource explicitly grants permission which marked itself as safe to be loaded by other origins, and thus doesn’t share sensitive information. If the value is set to same-origin, the resource will not load at all. And if no CORP or CORS headers are set, the request is allowed but credentials are stripped off.
Here’s the same image example as before but now the top-level document is served with COEP: credentialless. As you will notice, in the example with require-corp, the top three images didn’t load at all. By switching over to credentialless, there’s only one scenario that doesn’t work and it’s because the crossorigin attribute enforces CORS.
This seems like a much better option as it does not require changes on either the server or the application. Unfortunately, credentialless is not yet widely supported.
credentialless support
At the time of writing, Cross-Origin-Embedder-Policy: credentialless is only available in Chromium-based browsers and was shipped since Chrome 96. Firefox decided to start working on it but no estimation is provided when it will be available. As far as we know, the Safari team does not plan on implementing this feature, which is unfortunate because it blocks the rollout of cross-origin isolation at scale.
Conclusion
The reason StackBlitz currently only works in Chromium-based browsers is not because of some Chrome-specific APIs. The cross-origin isolation problem is a very complex and brittle mechanism. Everything has to be set correctly in order to not break anything. But as we saw before, websites which serve user-generated content like forums, Google Earth, and StackBlitz, face problems with deploying cross-origin isolation.
The reason StackBlitz works in Chromium-based desktop browsers today is because we use the origin trial. All other browsers, even Android Chrome, requires cross-origin isolation through the mechanisms described above.
The origin trial is currently the reason why embedding StackBlitz WebContainers-based projects just work without specific configuration on your end. And it’s also the reason why you are able to load any arbitrary resources without the need of a proxy server or specifying the correct headers. Cross-origin isolation is a complex matter and we can’t expect all our users to know what it means or how to resolve issues.
Future plans
Ideally, all browsers ship support for the new credentialless mode. But because we don’t want to wait on that, we are currently looking at implementing a hybrid approach based on the user’s browser. If the user is using a browser which support credentialless, we can serve StackBlitz in credentialless mode. In the other cases, we can fallback to require-corp.
However, users who use a browser which does not support credentialless, might be impacted by the issues explained above. In the end, it’s better to have some support than no support at all.
There are other issues we need to resolve in order to make cross-browser support fully-aligned. They are out of scope of this blogpost as all of them can be resolved. However, without the support of browser vendors, and the will to implement credentialles, more and more websites will suffer.
Let’s recap
- Due to the Spectre vulnerability in early 2018,
SharedArrayBufferand other features got disabled in all browsers. With new security mechanisms in place, it’s possible to re-enable them with cross-origin isolation. - By serving your document with the
Cross-Origin-Opener-PolicyandCross-Origin-Embedder-Policyheaders, you can make your document cross-origin isolated. - Cross-origin isolation is currently hard to roll out at scale due to it’s restrictions. OAuth flows are broken and websites with user-generated content from unknown parties can’t just load resources without additional changes.
- Embedding cross-origin isolated pages always require the top-level page to be cross-origin isolated as well. There are no proposals to allow a non-cross-origin isolated website to embed a cross-origin isolated website.
- The new
credentiallessproposal would solve almost all issues but is currently only available in Chromium-based browsers. Firefox is working on it, and as far as we know, Safari has no plans on implementing this feature. - StackBlitz is looking at a hybrid approach based on the user’s browser. However, browsers that do not support
credentiallesswill have a more limited experience based on their use case.



